# 架构概述
# 层次概述
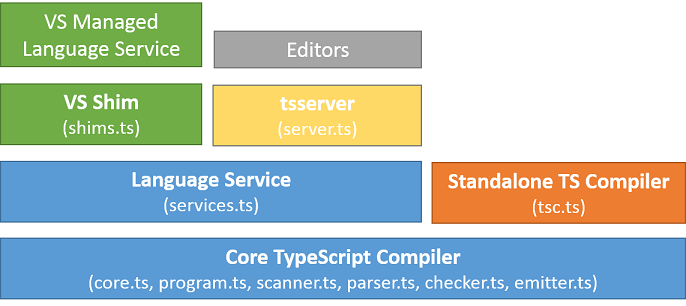
- 核心 TypeScript 编译器
- 语法分析器(Parser): 以一系列原文件开始,根据语言的语法,生成抽象语法树(AST)
- 联合器(Binder): 使用一个
Symbol将针对相同结构的声明联合在一起(例如:同一个接口或模块的不同声明,或拥有相同名字的函数和模块)。这能帮助类型系统推导出这些具名的声明。 - 类型解析器与检查器(Type resolver / Checker): 解析每种类型的构造,检查读写语义并生成适当的诊断信息。
- 生成器(Emitter): 从一系列输入文件(.ts 和.d.ts)生成输出,它们可以是以下形式之一:JavaScript(.js),声明(.d.ts),或者是 source maps(.js.map)。
- 预处理器(Pre-processor): “编译上下文” 指的是某个 “程序” 里涉及到的所有文件。上下文的创建是通过检查所有从命令行上传入编译器的文件,按顺序,然后再加入这些文件直接引用的其它文件或通过
import语句和/// <reference path=... />标签间接引用的其它文件。
沿着引用图走下来你会发现它是一个有序的源文件列表,它们组成了整个程序。 当解析导出(import)的时候,会优先选择 “.ts” 文件而不是 “.d.ts” 文件,以确保处理的是最新的文件。 编译器会进行与 Nodejs 相似的流程来解析导入,沿着目录链查找与将要导入相匹配的带.ts 或.d.ts 扩展名的文件。 导入失败不会报 error,因为可能已经声明了外部模块。
- 独立编译器(tsc): 批处理编译命令行界面。主要处理针对不同支持的引擎读写文件(比如:Node.js)。
- 语言服务: “语言服务” 在核心编译器管道上暴露了额外的一层,非常适合类编辑器的应用。
语言服务支持一系列典型的编辑器操作比如语句自动补全,函数签名提示,代码格式化和突出高亮,着色等。 基本的重构功能比如重命名,调试接口辅助功能比如验证断点,还有 TypeScript 特有的功能比如支持增量编译(在命令行上使用 --watch )。 语言服务是被设计用来有效的处理在一个长期存在的编译上下文中文件随着时间改变的情况;在这样的情况下,语言服务提供了与其它编译器接口不同的角度来处理程序和源文件。
请参考 [[Using the Language Service API]] 以了解更多详细内容。
# 数据结构
- Node: 抽象语法树(AST)的基本组成块。通常
Node表示语言语法里的非终结符;一些终结符保存在语法树里比如标识符和字面量。 - SourceFile: 给定源文件的 AST。
SourceFile本身是一个Node;它提供了额外的接口用来访问文件的源码,文件里的引用,文件里的标识符列表和文件里的某个位置与它对应的行号与列号的映射。 - Program:
SourceFile的集合和一系列编译选项代表一个编译单元。Program是类型系统和生成代码的主入口。 - Symbol: 具名的声明。
Symbols是做为联合的结果而创建。Symbols连接了树里的声明节点和其它对同一个实体的声明。Symbols是语义系统的基本构建块。 - Type:
Type是语义系统的其它部分。Type可能被命名(比如,类和接口),或匿名(比如,对象类型)。 - Signature: 一共有三种
Signature类型:调用签名(call),构造签名(construct)和索引签名(index)。
# 编译过程概述
整个过程从预处理开始。 预处理器会算出哪些文件参与编译,它会去查找如下引用( /// <reference path=... /> 标签和 import 语句)。
语法分析器(Parser)生成抽象语法树(AST) Node . 这些仅为用户输出的抽象表现,以树的形式。 一个 SourceFile 对象表示一个给定文件的 AST 并且带有一些额外的信息如文件名及源文件内容。
然后,联合器(Binder)处理 AST 节点,结合并生成 Symbols 。 一个 Symbol 会对应到一个命名实体。 这里有个一微妙的差别,几个声明节点可能会是名字相同的实体。 也就是说,有时候不同的 Node 具有相同的 Symbol ,并且每个 Symbol 保持跟踪它的声明节点。 比如,一个名字相同的 class 和 namespace 可以合并,并且拥有相同的 Symbol 。 联合器也会处理作用域,以确保每个 Symbol 都在正确的封闭作用域里创建。
生成 SourceFile (还带有它的 Symbols 们)是通过调用 createSourceFile API。
到目前为止, Symbol 代表的命名实体可以在单个文件里看到,但是有些声明可以从多文件合并,因此下一步就是构建一个全局的包含所有文件的视图,也就是创建一个 Program 。
一个 Program 是 SourceFile 的集合并带有一系列 CompilerOptions 。 通过调用 createProgram API 来创建 Program 。
通过一个 Program 实例创建 TypeChecker 。 TypeChecker 是 TypeScript 类型系统的核心。 它负责计算出不同文件里的 Symbols 之间的关系,将 Type 赋值给 Symbol ,并生成任何语义 Diagnostic (比如:error)。
TypeChecker 首先要做的是合并不同的 SourceFile 里的 Symbol 到一个单独的视图,创建单一的 Symbol 表,合并所有普通的 Symbol (比如:不同文件里的 namespace )。
在原始状态初始化完成后, TypeChecker 就可以解决关于这个程序的任何问题了。 这些 “问题” 可以是:
- 这个
Node的Symbol是什么? - 这个
Symbol的Type是什么? - 在 AST 的某个部分里有哪些
Symbol是可见的? - 某个函数声明的
Signature都有哪些? - 针对某个文件应该报哪些错误?
TypeChecker 计算所有东西都是 “懒惰的”;为了回答一个问题它仅 “解决” 必要的信息。 TypeChecker 仅会检测和这个问题有关的 Node , Symbol 或 Type ,不会检测额外的实体。
对于一个 Program 同样会生成一个 Emitter 。 Emitter 负责生成给定 SourceFile 的输出;它包括: .js , .jsx , .d.ts 和 .js.map 。
# 术语
# 完整开始 / 令牌开始(Full Start/Token Start)
令牌本身就具有我们称为一个 “完整开始” 和一个 “令牌开始”。“令牌开始” 是指更自然的版本,它表示在文件中令牌开始的位置。“完整开始” 是指从上一个有意义的令牌之后扫描器开始扫描的起始位置。当关心琐事时,我们往往更关心完整开始。
| 函数 | 描述 |
|---|---|
ts.Node.getStart | 取得某节点的第一个令牌起始位置。 |
ts.Node.getFullStart | 取得某节点拥有的第一个令牌的完整开始。 |
# 琐碎内容(Trivia)
语法的琐碎内容代表源码里那些对理解代码无关紧要的内容,比如空白,注释甚至一些冲突的标记。
因为琐碎内容不是语言正常语法的一部分(不包括 ECMAScript API 规范)并且可能在任意 2 个令牌中的任意位置出现,它们不会包含在语法树里。但是,因为它们对于像重构和维护高保真源码很重要,所以需要的时候还是能够通过我们的 APIs 访问。
因为 EndOfFileToken 后面可以没有任何内容(令牌和琐碎内容),所有琐碎内容自然地在非琐碎内容之前,而且存在于那个令牌的 “完整开始” 和 “令牌开始” 之间。
虽然这个一个方便的标记法来说明一个注释 “属于” 一个 Node 。比如,在下面的例子里,可以明显看出 genie 函数拥有两个注释:
var x = 10; // This is x.
/**
* Postcondition: Grants all three wishes.
*/
function genie([wish1, wish2, wish3]: [Wish, Wish, Wish]) {
while (true) {}
} // End function
这是尽管事实上,函数声明的完整开始是在 var x = 10; 后。
我们依据 Roslyn's notion of trivia ownership (opens new window) 处理注释所有权。通常来讲,一个令牌拥有同一行上的所有的琐碎内容直到下一个令牌开始。任何出现在这行之后的注释都属于下一个令牌。源文件的第一个令牌拥有所有的初始琐碎内容,并且最后面的一系列琐碎内容会添加到 end-of-file 令牌上。
对于大多数普通用户,注释是 “有趣的” 琐碎内容。属于一个节点的注释内容可以通过下面的函数来获取:
| 函数 | 描述 |
|---|---|
ts.getLeadingCommentRanges | 提供源文件和一个指定位置,返回指定位置后的第一个换行与令牌之间的注释的范围(与 ts.Node.getFullStart 配合会更有用)。 |
ts.getTrailingCommentRanges | 提供源文件和一个指定位置,返回到指定位置后第一个换行为止的注释的范围(与 ts.Node.getEnd 配合会更有用)。 |
做为例子,假设有下面一部分源代码:
debugger;/*hello*/
//bye
/*hi*/ function
function 关键字的完整开始是从 /*hello*/ 注释,但是 getLeadingCommentRanges 仅会返回后面 2 个注释:
d e b u g g e r ; / * h e l l o * / _ _ _ _ _ [CR] [NL] _ _ _ _ / / b y e [CR] [NL] _ _ / * h i * / _ _ _ _ f u n c t i o n
↑ ↑ ↑ ↑ ↑
完整开始 查找 第一个注释 第二个注释 令牌开始
开始注释
适当地,在 debugger 语句后调用 getTrailingCommentRanges 可以提取出 /*hello*/ 注释。
如果你关心令牌流的更多信息, createScanner 也有一个 skipTrivia 标记,你可以设置成 false ,然后使用 setText / setTextPos 来扫描文件里的不同位置。